Shortcuts
Shortcuts



3.1 Overview of publishing biodiversity dataset through GBIF
A dataset includes metadata and raw data. The simplest dataset can just only include metadata. Currently, there are four types of datasets GBIF supported to publish: 1) metadata-only, 2) checklist, 3) occurrence, and 4) sampling-event datasets, with increasing richness in data content and complexity in data structure. To preserve the completeness of a dataset we suggest data providers publish the richest datasets as possible as they can.
To publish a dataset on the web is just like to produce a data product. Metadata is just like the specification and manual of a product. It tells the users about the content, usage of the product, information for customer services, etc. In other words, metadata may tell you how the data came from, how to use the data, whom you can contact with if you have any question about the data, etc. A product is a kind of resource, therefore, a dataset is also a resource on the web. In context of GBIF, dataset is one kind of resource. For publishing a dataset (or resource) via GBIF, you have to prepare resource metadata with checklist, occurrence, or sampling-event data using a collection of terms in the DarwinCore Extensions as the standardized column names in the data tables of your checklist, occurrence, or sampling-event data.
The simple way to prepare your dataset is to use an Excel template with predefined format to fill in the metadata and raw data. This will help you easily organize your data into the standardized data structure accepted by GBIF. GBIF provides simple Excel templates, which include DarwinCore terms as the standardized column names.
However, when you have a huge data table, for example, more ten thousand records, you will find it is not easy to handle too many records using Excel. In that situation, we will suggest you use R, an open source statistical and data-processing software. If you are new to R, we encourage you learn R because it is one of the most popular tools for data analysis. In this chapter, we will show you how to use Excel template and R-scripts to prepare a sampling-event dataset.
3.2 What is sampling-event data?
Sometimes datasets can provide far more information than you might imagine, not just where and when a species was discovered, but also the opportunity to discover the community composition of a broader taxonomic group or species abundance at different times and places. These datasets typically come from standard operating procedures for measuring and monitoring biodiversity, such as transect surveys of plant communities, bird survey programs, freshwater and marine sampling. By indicating the methods, events, and relative abundances of species used to record the samples, these datasets can enhance comparisons between data collected at different times and locations under the same standard operating procedures, and sometimes even allow researchers to discover the absence of species in certain locations. (Original reference: http://www.gbif.org/publishing-data/summary)
3.2.1 Selected core terms for Sampling Event + Location
(**Required)| 調查活動識別碼(eventID**) | 最低海拔(公尺)(minimumElevationInMeters) |
| 父階調查活動識別碼(parentEventID) | 最高海拔(公尺) (maximumElevationInMeters) |
| 調查活動日期(eventDate**) | 最小深度(公尺) (minimumDepthInMeters) |
| 棲息地(Habitat) | 最大深度(公尺) (maximumDepthInMeters) |
| 調查採樣流程(samplingProtocol**) | 與海平面最小距離(公尺) (minimumDistanceAboveSurfaceIn Meters) |
| 樣本大小值(sampleSizeValue**) | 與海平面最大距離(公尺) (maximumDistanceAboveSurfaceIn Meters) |
| 樣本大小單位(sampleSizeUnit**) | 洲(Continent) |
| 調查採樣努力量(samplingEffort) | 國家(Country) |
| 地點識別碼(locationID) | 國碼(countryCode) |
| 十進位緯度(decimalLatitude) | 州/省(stateProvince) |
| 十進位經度(decimalLongitude) | 縣(Country) |
| 大地基準(geodeticDatum) | 市(Municipality) |
| 座標誤差(公尺)(coordinateUncertaintyInMeters*) | 地點(locality) |
| 座標精確度(coordinatePrecision*) |
Reference: http://tools.gbif.org/dwca-validator/extension.do?id=dwc:Event
3.2.2 MeasurementOrFact Core Terms
- 調查活動識別碼(eventID**)
- 測量識別碼(measurementID
- 測量類型(measurementType)
- 測量值(measurementValue)
- 測量準確度(measurementAccuracy)
- 測量單位(measurementUnit)
- 測量確認者(measurementDeterminedBy)
- 測量確認日期(measurementDeterminedDate)
- 測量方法(measurementMethod)
- 測量備註(measurementRemarks)
Reference: http://tools.gbif.org/dwca-validator/extension.do?id=dwc:MeasurementOrFact
3.2.3 Selected core terms for Occurrence + Taxon
| 調查活動識別碼(eventID**) | 個體數(individualCount) |
| 出現紀錄識別碼(occurrenceID**) | 生物體數量(organismQuantity) |
| 學名識別碼(scientificNameID) | 生物體數量類別(organismQuantityType) |
| 學名(scientificName) | 性別(sex) |
| 分類識別碼(taxonID) | 生活史階段(lifestage) |
| 俗名(vernacularName) | 繁殖狀況(reproductiveCondition) |
| 分類階層(taxonRank) | 行為(behavior) |
| 界(kingdom) | 出現紀錄狀態(occurrenceStatus) |
| 門(phylum) | 有效學名使用名稱識別碼(acceptedNameUsageID) |
| 綱(class) | 有效學名使用名稱(acceptedNameUsage) |
| 目(order) | 種小名(specificEpithet) |
| 科(family) | 亞種小名(infraspecificEpithet) |
| 屬(genus) | 學名命名者(scientificNameAuthorship) |
| 記錄者(recordedBy) |
Reference: http://tools.gbif.org/dwca-validator/extension.do?id=dwc:Occurrence
3.3 Darwin Core - Sampling-event Star Schema

3.3.1 Star schema
GBIF 的發布資料結構如上圖所示(以調查活動為例),在發布資料前,先確認你的研究資料類型是屬於名錄、出現紀錄還是調查活動,並以該類型資料結構為基礎(Core核心集)去設定資料表的欄位名稱(參照 Darwin Core),而其他未被包含於核心集的資料,則可以選擇其他類型的欄位名稱,整理成延伸集(可視為核心集的補充說明)。所有的延伸集都必須能有一個欄位(強烈建議為唯一識別碼ID)與核心集相同,才能相互對應,追溯到同一批次的資料。可以把這些想像成一個excel表,主頁資料就是核心集,其他分頁都是延伸集,內容皆與主頁有關。
3.3.2 How to publish data?
- Prepare raw data
- Check and Clean the data (correct scientific names or other errors)
- Adopt terms of Darwin Core Event vocabulary and MeasureOrFacts. Occurrence, … extensions as the column names of your data table
- Transform data structure innto separate tables fitted into DarwinCore star-schema and save the tables as UTF-8 encoded CSV text files
- Prepare metadata
- Register an account on the IPT hosted by the node (such as TaiBIF), which endorse your orgainzation as a data publishing orgainzation
- Log into the IPT, create a new resource, upload your data tables and do DarwinCore mappings
- Provide metadata
- Publish the data


What is sampling-event data?
http://github.com/gbif/ipt/wiki/samplingEventData#exemplar-datasets
大致流程:
確認資料的種類 >> 轉換資料 >> 上傳資料至IPT >> 將資料對應至調查活動及出現紀錄 >> 填入詮釋資料 >> 發布資料集 >> 完成資料集註冊
3.4 Prepare sampling-event data using Excel template
Example dataset annd tools for preparing data
- Data file: 1_AlienPlantSurvey.xlsx
- MS Excel / LibreOffice Calc
- Text editor: Notepad++ / PSPad / …
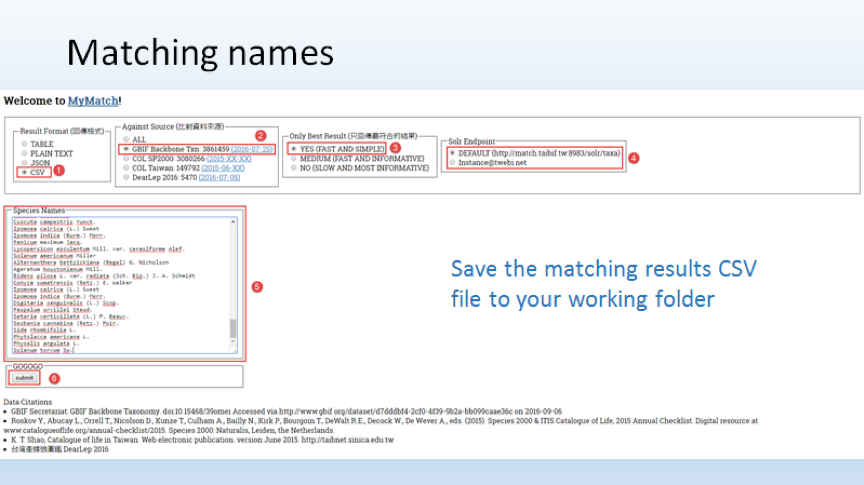
- TaiBIF Scientific names matching service (Nomenmatch): (http://match.taibif.tw)
Example data file
- 1_AlienPlantSurvey.xlsx
- 7 tables
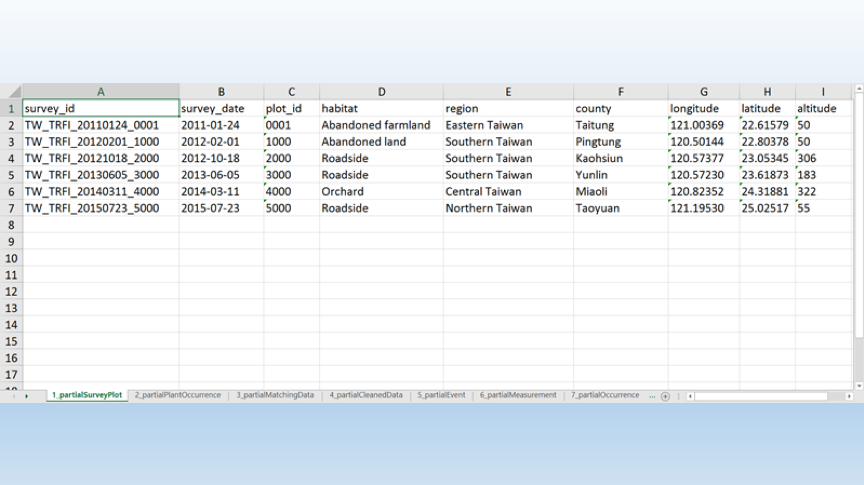
- 部分調查樣區(partialSurveyPlot)
- 部分植物出現紀錄(partialplantOccurrence)
- 部分已對應資料(partialMatchingData)
- 部分已清理資料(partialCleanedData)
- 部分調查活動(partialEvent)
- 部分測量值(partialMeasurement)
- 部分出現紀錄(partialOccurrence)

Data cleaning and transformation workflow
- Check and study the original data structure
- Check the spelling of the input scientific name using matching service and get the matching results CSV text file
- Using the Notepad++ to open the matching results file and copy all text and paste into an spreadsheet table
- Cleaning names based on the matching results and get data of taxonRank and names for higher taxonomic ranks
- Create Event, MeasurementOrFacts, and Occurrence tables
- Mapping original column names to Darwin Core terms
- Copy data of Event, Measurement, Occurrence tables respectively into Notepad++, encoded in UTF-8, then save as CSV text files